Understanding Temporal Locality
When writing a program, it is tempting to try to count instructions to analyze its performance. Clearly a program that runs 100 instructions should be faster than one that runs 110. But many factors can muddy the analysis.
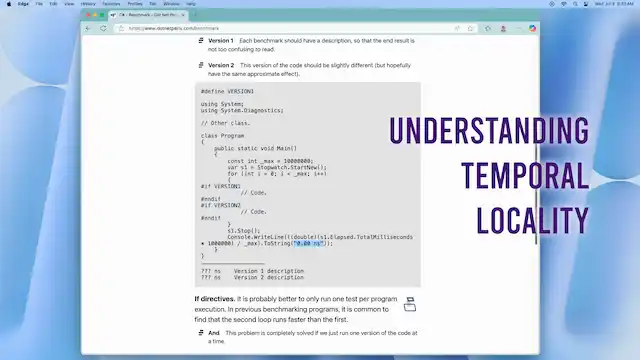
Consider the processor's memory cache—if we load a file from the disk into memory, we can access that file again with minimal delay as it is in the CPU cache. This means that operations that act on a region of memory are faster if they are done nearer in time to one another.
This concept is known as temporal locality, and it has some implications:
At times I have had a program that opens many files, and then tries to process them all at once. But by understanding temporal locality, it is possible to optimize for the CPU cache—we open a file, process it fully, and then move to the next file. This can lead to a measurable performance improvement.