Gemma3 4B Local LLM Review
About three months ago, Google released its open-weights Gemma 3 LLMs. These models can be downloaded and run on computers with enough RAM using the Ollama program. This is fine—but are the models worth bothering with?
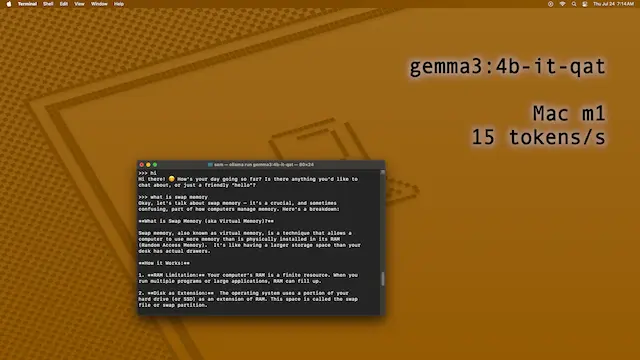
To test, I downloaded the 4B models, as my Mac mini M1 with 8 GB of RAM cannot run anything larger than that. The gemma3 4B QAT (quantization-aware training) model has 4.3 billion parameters and can run on the unified 8 GB memory of the Mac mini M1. Not only this, but Ollama supports GPU-acceleration of the model, so it is fairly fast in responding.
I tested the default gemma3 4B quantized model, and the QAT model, and my findings are that:
QAT is indeed better at providing answers than the non-QAT model, so I would always recommend the QAT models (look for "qat" in the model name).QAT generates about 15 tokens per second on the M1 chip and 8 GB of RAM.4B-IT-QAT model causes macOS to use about a gigabyte of swap memory, even when doing light web browsing.Definitely prefer QAT—there are cases where the QAT models got the answer right, and the default model did not. Gemma3 has an enjoyable style, and it uses emoticons in its greetings. It is a friendly, and even useful, assistant—it is possible to use it with only 8 GB of RAM on a Mac, but 16 GB would allow faster operation of the computer without swapping.